Nitenje z orodjem OpenMP
Osnovni koncept pisanja vzporednih programov z orodjem OpenMP temelji na nitenju programa. To je postopek, s katerim program razcepimo v več niti (vsaka nit je ločen tok strojnih ukazov), ki se vsaka od sebe izvaja neodvisno od drugih. Program se med izvajanjem lahko večkrat razcepi v različne skupine niti, pač v skladu s potrebami reševanja določenega problema.
Opozorilo pred nadaljevanjem: Marsikatero trditev, ki jo bomo zapisali v nadaljevanju, bomo kasneje dopolnili (ali navidez celo spremenili). A za tak način imamo tehten razlog: mnogi elementi orodja OpenMP imajo veliko število nastavitev, pri sprotni razlagi pa se bomo osredotočili na koncepte, ne na nastavitve (ki pogosto pomembno spremenijo učinek posameznih elementov).
Enostavno nitenje
Klasični programi se izvajajo zaporedno. To pomeni, da v procesor teče en tok ukazov, ki jih jedro procesorja izvaja enega za drugim. Orodje OpenMP omogoča enostavno in učinkovito nitenje programa. To pomeni, da se program na neki točki razcepi v skupino niti, od katerih vsaka nit teče skozi procesor kot svoj tok ukazov neodvisno od drugih niti. Če je na voljo dovolj procesorjev ali procesorskih jeder, se te niti izvajajo vzporedno. Niti se lahko v nekem trenutku spet združijo v en sam tok ukazov, nitenje pa se s tem konča. Seveda se lahko v istem programu nitenje lahko izvede večkrat.
Za hip se vrnimo k programu hello-world-1, ki smo ga uporabili pri pripravi delovnega okolja:
1 2 3 4 5 6 7 8 9 10 11 | |
Ko ta program poženemo, se začne izvajati zaporedno, torej kot ena (glavna) nit. Prvi klic funkcije printf (vrstica 6) se torej izvede povsem običajno, ukaz #pragma omp parallel pa določi, da se bo naslednji stavek izvedel večkrat, vsakič v eni niti. To pomeni, da bo tik pred izvedbo drugega klica funkcije printf (vrstica 8) program ustvaril določeno skupino niti in vsaka nit posebej bo izvedla klic funkcije printf. Ko vse niti zaključijo z delom, se ponovno združijo v eno (glavno) nit, saj je na koncu dela programa, ki spada pod ukaz #pragma omp parallel, avtomatsko vključena sinhronizacijska pregrada. Tretji klic funkcije printf in stavek return (vrstici 9 in 10) se bosta znova izvšila v eni sami (glavni) niti. Tak način izvajanja prikazuje slika 5.
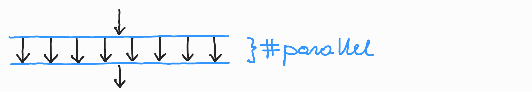
Slika 5: Nitenje programa hello-world-1.
Če poženemo program hello-world-1 na sistemu s podporo za 8 strojnih niti, dobimo pričakovan izpis (le zaporedje izpisa oznak niti bo vsakič drugačno):
Hello world: 0 2 4 5 6 7 1 3
Seveda pa lahko nitenje v programu izvedemo večkrat, recimo takole:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
V programu hello-world-2 se nitenje izvede v vsakem obratu for zanke, torej se program izvaja tako, kot kaže slika 6.
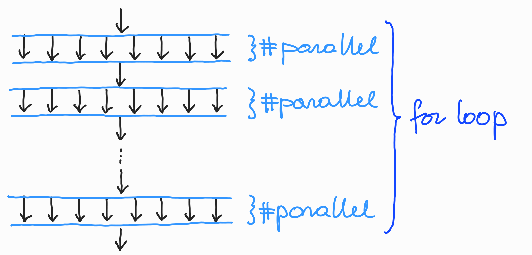
Slika 6: Nitenje programa hello-world-2.
Če poženemo program hello-world-2, dobimo naslednji izpis:
Hello world:
0 7 1 5 3 4 6 2
7 1 2 5 4 6 0 3
1 2 6 7 5 3 0 4
1 6 5 0 3 2 4 7
Če ta program izvedemo večkrat, bodo oznake niti v posameznih vrsticah vsakič na novo premešane, a izpis bo vsakič lepo urejen po vrsticah: vsak obrat for zanke ustvari svoje nitenje, ki se zaključi, preden se izpiše znak za novo vrstico.
Program hello-world-2 lahko prepišemo drugače:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Tokrat ustvarimo nitenje le enkrat, za razliko od programa hello-world-2 vsaka nit programa hello-world-3 večkrat izpiše svojo oznako in potem sama izpiše tudi znak na novo vrstico. Program se torej izvaja tako, kot kaže slika 7.
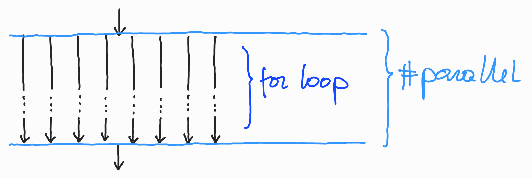
Slika 7: Nitenje programa hello-world-3.
Drugačno izvajanje programa povzroči tudi drugačen izpis:
Hello world:
1 3 7 0 0 0 2 2 7 7 7 4
1 0 1 1
4 4 4
2 2
6 6 6 6
3 3 3
5 5 5 5
Niti se namreč izvajajo hkrati in medsebojno niso sinhronizirane. Brez eksplicitne zahteve po sinhronizaciji (a o tem kasneje) se niti sinhronizirajo le na pregradi ob koncu izvajanja dela kode, ki spada pod ukaz #pragma omp parallel, torej pri izhodu iz bloka v vrsticah od 8 do 12.
Število niti ter povezava med programskimi in strojnimi nitmi
Če tako kot v vseh programih dosedaj števila niti ne določimo posebej, program uporabi toliko niti, kot jih sistem zmore sočasno izvati glede na razpoložljivo strojno podporo. Seveda pa lahko število niti v programu določimo drugače. Za to imamo tri možnosti:
- z uporabo spremenljivke
OMP_NUM_THREADSv ukazni lupini; - z uporabo funkcije
omp_set_num_threadspred ukazom#pragma omp parallel; - z uporaba dopolnila
num_threadsv direktivi#pragma omp parallel.
V ukazni vrstici določimo število programskih niti določimo takole:
$ env OMP_NUM_THREADS=8 ./hello-world-1
Hello world: 3 0 6 4 2 5 7 1
env OMP_NUM_THREADS=8 ./hello-world-1
V programu to lahko naredimo na dva načina, torej s funkcijo omp_set_num_threads
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
ali z uporabo dopolnila num_threads
1 2 3 4 5 6 7 8 9 10 11 12 | |
Vaja
Vse tri pristope lahko v programu uporabljamo hkrati.
Kaj se zgodi ob uporabi dveh ali treh pristopov v istem programu? Zakaj?
Namig: Najprej poskusite in premislite, šele potem poglejte v specifikacijo.
Programske niti (v nadaljevanju zgolj niti) se izvedejo na posameznih strojnih nitih, torej na različnih procesorjih, jedrih ali nitih (če se uporablja hipernitenje). Operacijski sistem lahko med izvajanjem posamezno programsko nit večkrat prestavi z ene strojne niti na drugo. To počne predvsem z namenom enkomerne porazdelitve dela med strojnimi nitmi.
Programskih niti je lahko precej več kot strojnih niti: na sistemu z 2 procesorjema s po 4 jedri in izključenim hipernitenjem imamo torej 8 strojnih niti, program pa zlahka uporablja nekaj 1000 programskih niti, ki jih operacijski sistem potem izvede na 8 strojnih nitih.
Povzetek
Del programa, za katerega želimo, da se izvede večnitno, označimo z direktivo
#pragma omp parallel seznam-določil
stavek-ali-blok
Pri tem stavek-ali-blok označuje enostaven stavek (kot recimo v programih hello-world-1 in hello-world-2) ali skupino stavkov združenih v sestavljeni stavek (kot recimo v programu hello-world-3).
Med izvajanjem programa se posebej za stavek-ali-blok ustravi skupina niti, od katerih vsaka neodvisno izvede stavek-ali-blok. Ko (in šele ko) vse niti končajo z izvajanjem, se sinhronizirajo.
(Morebiti prazen) seznam z vejicami ločenih določil vsebuje dodatna dopolnila, kako naj program izvede nitenje. Eno takih določil je num_threads (v programu hello-world-5); ostala bomo po potrebi spoznali v nadaljevanju.