Programming Paradigms
First, we must understand that describing hardware using RTL or higher-level languages differs from writing programs executed on a general-purpose CPU. HLS tools cannot transform arbitrary software code into hardware - think of recursion, dynamic memory allocation, system calls, standard libraries, etc. However, we are very flexible in implementing certain computations in hardware. Thus, the designer must provide hints about the most efficient design. In this section, we will learn how to assist the HLS tool in achieving the desired level of performance using directives or suggestions called #pragma.
To design efficient, custom-made digital systems using FPGAs, we need to follow specific patterns of code-writing, also known as paradigms. There are three paradigms for programming FPGAs:
- Producer-consumer
- Streaming data
- Pipelining
Before delving into each paradigm, let's discuss the crucial step: understanding the program's workflow. Initially, we need to identify the program's independent tasks that can run in parallel. This approach enhances the system's throughput.
For example, imagine designing a music player that reads audio data from an SD card, decodes it, and generates a signal on the audio output. Initially, we might view this as a sequential process with the following tasks:
- Read the data from the SD card.
- Decode the data.
- Generate an output signal.

However, in this workflow, there are inherent overlaps — tasks that can be executed in parallel. Instead of reading all the SD card data blocks and proceeding to the decoding task, we can overlap them. So, while reading the second block, the decoder can begin processing the first block. There's no need to wait. The same applies to the third task. As soon as a block of audio data is decoded, we can use it to generate an output signal, producing audible sound over the connected loudspeaker.
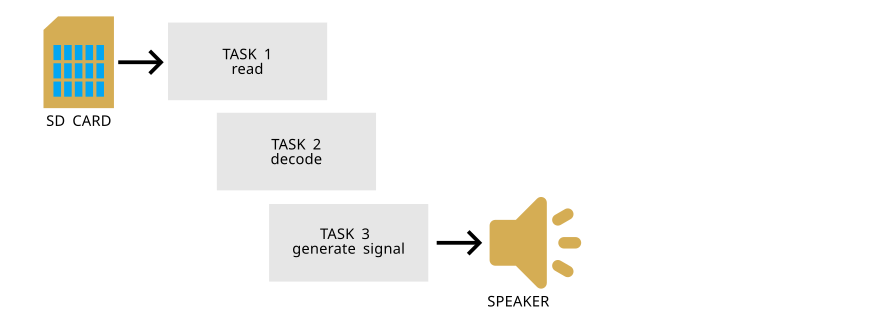
Producer-Consumer Paradigm
This paradigm divides processing tasks into two main components: producers and consumers. They communicate over a shared buffer or queue, typically a first-in-first-out (FIFO) or ping-pong (PIPO) buffer.
Producers generate data and place it into a queue. A producer could represent modules or processes that create data, such as sensor readings, video frames, or any other input form.
Shared queue holds the data produced by producers until consumers are ready to process it. In FPGAs, we could implement this queue using on-chip memory in distributed RAM (using LUTs), BRAM, or URAM.
Consumers retrieve and process the data from the shared queue. These components perform specific tasks or computations based on the incoming data.
The producer-consumer paradigm is beneficial in scenarios where the data production and consumption rate can vary or is asynchronous. This paradigm is often employed in systems such as data streaming, where data is continuously generated and processed.
Let's illustrate the paradigm using the example of a music player described previously. For simplicity, let's focus only on one producer (reading input data) and one consumer (decoder). They communicate over a finite-size buffer, as seen in the figure below. If the buffer is full, the producer blocks and stops reading blocks of data from the SD card. When the consumer decodes a block of data and removes it from the buffer, it notifies the producer, who resumes filling the buffer. Similarly, when the buffer is empty, the consumer stalls. The producer wakes the consumer when a new data block arrives in the buffer.

In this form of macro-level architectural optimization using a communication queue, the complexities of a parallel program are effectively abstracted away. The programmer does not need to worry about memory models and other non-deterministic behaviors like race conditions.
Streaming Data Paradigm
Stream is a continuously updating set of data pieces where we do not know the number of blocks in advance. As we discussed before, a stream can be seen as a sequence of data blocks that flows between producer and consumer. This streaming paradigm encourages us to think about data access patterns, favoring sequential accesses over random-access-memory comfort, which is common in software design. Making sequential memory accesses that can be converted into streams of scalars or buffers is very beneficial.
For example, in a streaming dataflow network, let's suppose a scenario where two proximity sensors (e.g., in a car) serve as streaming data sources. We use two sensors instead of only one to provide redundancy and minimize the impact of potential sensor failures. Task 1 and Task 2 are responsible for reading data from these sensors. The streaming data is then sent over FIFO queues to Task 3, which calculates the average of the sensor readings. Subsequently, using another FIFO queue, Task 4 writes the computed average to a log for further analysis or monitoring. The FIFO queues provide asynchronous buffering between these independent execution paths.
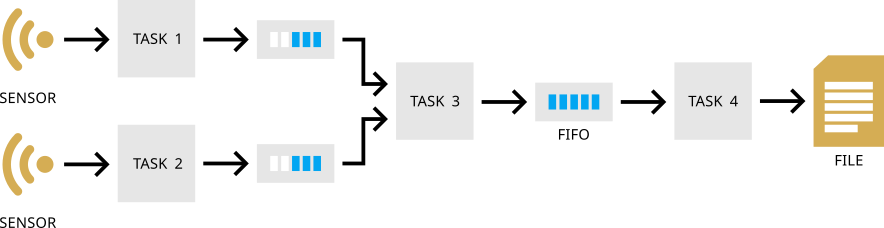
Decomposing algorithms into producer-consumer relationships with streaming communication offers advantages such as sequential algorithm definition, automatic parallelism extraction, and abstraction of complexities like synchronization between tasks. The producer and consumer tasks can process data simultaneously, promoting higher throughput and cleaner code.
Pipelining Paradigm
Pipelining is a concept frequently encountered in everyday life, and a sandwich shop's production line provides an apt example. In this scenario, specific tasks, such as spreading mayonnaise on a slice of bread (Task 1), placing cheese and tomatoes (Task 2), and the final assembly with another piece of bread and wrapping (Task 3), are assigned to separate workstations. Each workstation handles its task in parallel, focusing on different sandwiches. Once a sandwich undergoes one task, it progresses to the subsequent workstation. In hardware design, workstations are typically called stages.
Suppose the completion times for the tasks are 10 seconds for mayonnaise coating, 5 seconds for cheese and tomato placing, and 15 seconds for final assembly and wrapping. If all tasks were performed at a single workstation, the shop would produce one sandwich every 30 seconds. However, implementing a pipeline with three stages allows the shop to output the first sandwich in 30 seconds and subsequent sandwiches every 15 seconds.
Pipelining doesn't reduce the time for one sandwich to traverse the entire process (latency). Still, it significantly increases the throughput — the rate at which new sandwiches are processed after the first one. Balancing the workload among stages to ensure similar task completion times is essential for optimal throughput. In this example, we could divide the workload more evenly: let Task 2 also include the assembly of a sandwich with another slice of bread, leaving Task 3 with wrapping only. The effect is that each task now takes the same time (10 seconds) to complete. The latency is still 30 seconds, but a new sandwich comes out of the shop every 10 seconds instead of 15.
The figure below shows that the total latency for producing three sandwiches in a sequential line would be 90 seconds. In contrast, a pipelined production line would achieve the same output in only 50 seconds.
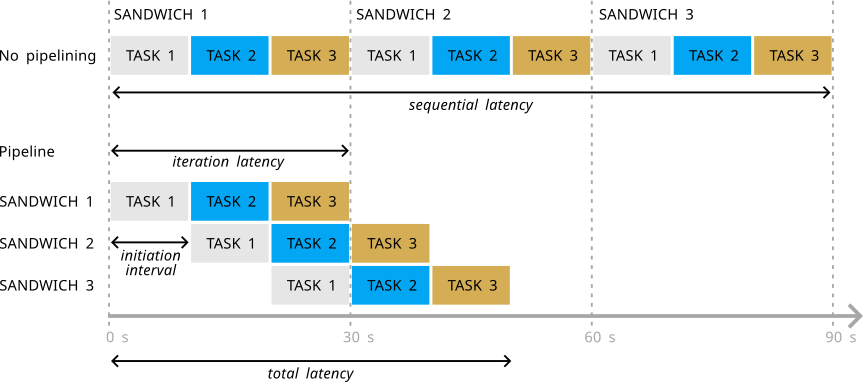
The time to produce the first sandwich is 30 seconds (iteration latency), and subsequent sandwiches take 10 seconds each (initiation interval). The overall time to produce three sandwiches is 50 seconds, representing the total latency of the pipeline.
total latency = iteration latency + initiation interval * (number of items - 1)
Improving the initiation interval enhances the total latency, demonstrating the effectiveness of the pipelining paradigm in optimizing throughput in sandwich production.
We said before that the consumer-producer paradigm represents macro-level architectural optimization. The pipelining paradigm is a typical micro-level optimization technique used on different levels: we explain pipelining on a task level with an example of a music player. We could also apply the same concept in a more fine-grained fashion on a level of instruction within the tasks. We need instruction-level pipelining to implement the producer-consumer model efficiently, where each task must produce or consume data blocks at a high rate to keep the stream flowing.
Static optimization
We consider pipelining a static optimization because it utilizes the same resources to execute the same function over time. This approach requires complete knowledge of each task's latency. Consequently, fine-grained instruction-level pipelining is unsuitable for dataflow-type networks where task latency depends on input data, making it unknown.
Take-home message
A cat is not a dog.
FPGA is not CPU.
Mind the hardware.
To achieve the desired performance on FPGA devices, consider these steps:
- Begin by concentrating on the macro-architecture of your design. Explore the possibility of modeling your solution using the producer-consumer paradigm.
- Draw the desired activity timeline where the horizontal axis represents time. This will give you a sense of the expected parallelism in the design.
- Start writing the code.
- Break down the original algorithm into smaller components that communicate through streams. Think about the granularity of the streaming (block size).
- Throughput is crucial. Have an overall understanding of the required processing rates for each phase or task in your design.